반갑습니다!!!
오늘은 저녁에 뭔가 인강듣기는 싫고,, 복습하기도 싫어서
C언어의 소스코드는 어떻게 생겼나 훔쳐봤습니다.
여러가지를 보다가 재미있는걸 발견했는데, 공유하기 위해서 저도 씁니다^^
c++의 sort는 여러가지 소트를 합친걸로 알고있습니다. Tim,intro, heap,quick 등등.. 여러개를 합쳤는데요.
예전에 알고리즘 수업에서 과제 중 하나가, 어떤 숫자에서도(숫자 몇십억개가 넘는) 가장 빠른 정렬을 할 수 있는 코드를 짜는게 숙제였습니다.
그걸로 학생들의 시간을 측정해서 차등으로 성적을 매겨줬습니다.
그때 굉장히 많이 찾아봤었는데, 저는 median-of-three라는 pivot 설정으로 quicksort를 짰는데, pivot 고르는걸 잘못했는지.. 어디 하자가 있어서 특정 distribution에서 소트를 하지 못하고 터져버렸습니다.
이때 그냥 mergesort 하니까 터지는건 없이 안전했는데.. 뭐 이때 생각도 나서 qsort를 봤습니다.
그 당시에 항상 거의 ? 대부분 C의 qsort < 내 코드(특정 분포에서 엄청 강함) <= c++ sort함수 였던것 같습니다.
https://code.woboq.org/userspace/glibc/stdlib/qsort.c.html
qsort.c source code [glibc/stdlib/qsort.c] - Woboq Code Browser
89_quicksort (void *const pbase, size_t total_elems, size_t size,
code.woboq.org
여기서 볼 수 있습니다.
qsort의 규칙이 있습니다.
1. recursive 멈춰!!!! 명시적인 stack의 pointer를 이용해서 값을 저장하고, 다음 위치로 이동한다고 합니다.
push,pop 등이 있는데, 사실 이건 아직 잘 모르겠어요. 아니 내가 이거까지 다 했으면 석박했지!! 인정합니다.

이 스택으로 partioning을 하는것 같아요.
full size로 담으면, 32bit integer 기준으로 32* sizeof(stack_node) == 256byte가 나옵니다
why? 32 * (포인터2개 8byte) = 2^8 = 256byte입니다. 64bit 면 64 * 포인터2개 16byte 여서 =1024byte인가봅니다.
근데 저 32,64가 비트당 말하는건지.. 뭔말인가 잘 이해가 안가네요
아무튼 저것만 쓰고도 퀵소트가 된다고하네요. pretty cheap 이럽니다 ㅋ..
2.
median-of-three 로 pivot을 잡는다고 합니다. 이 방식은 검색을 해보시면 될 것 같아요.
저도 가물가물 하네요.. 아무튼 이건 mid pivot, left pivot 이런것보다 좀 더 확률적으로 좋은 피봇을 잡을 확률이 높다고 했습니다.
수학적으로 증명을 해줬는데, 결과만 외웠습니다. 여기까지..
*중요한점. Threshold를 4로 줬습니다. 이게 무슨말이냐?
전체 원소 / Threshold 정도의 개수만 남으면, divide 해서 정렬하는것 보다 insertion sort를 사용합니다.
이게 더 빠르기 때문입니다. (이미 대부분 정렬이 되어있어서요)
원소가 32개면 약 8개정도남으면 그렇게 하나봐요.
참고로 insertion sort는 O(N^2)이지만, 거의 정렬이 되면 O(N) 수준인거 아시죠? 여기서 쓰네요 오우..
3. 2개의 sub-partition에서 큰걸 먼저 스택에 넣고, 작은걸 먼저 처리하라고 하네요.
이게 스택 사이즈가 log(total_size)보다 클 필요가 없어서 라는데.. 뭔소린지;;
차분하게 앉아서 읽어보고 싶은데.. 시간이 1시 30분이라 일단 자야겠습니다
암튼 ..
결론 :
qsort는 진짜 말 그대로
quick sort + insertion sort로 구성되어있다.
recursive를 안쓴다, Threshold를 이용해서 insertion으로 전환한다.
스택을 이용한다.
pivot을 median-of-three를 이용한다.
재미있는 부분
아 그리고 여기는 2로 나눌때 >> 1로 하더라고요.
비트연산자로 나누는게 속도가 빠른걸로 알았는데, 컴파일러가 컴파일 할때 / 2라고 해도 shift 연산으로 변환을 합니다.
그래서 컴파일 시간만 줄어들고, 실행속도는 차이 없을거라고 알고 있었습니다.(예전에 수업만 듣고 교수님께 질문하기 전에)
컴파일러의 역할을 coder가 대신해주는거죠.
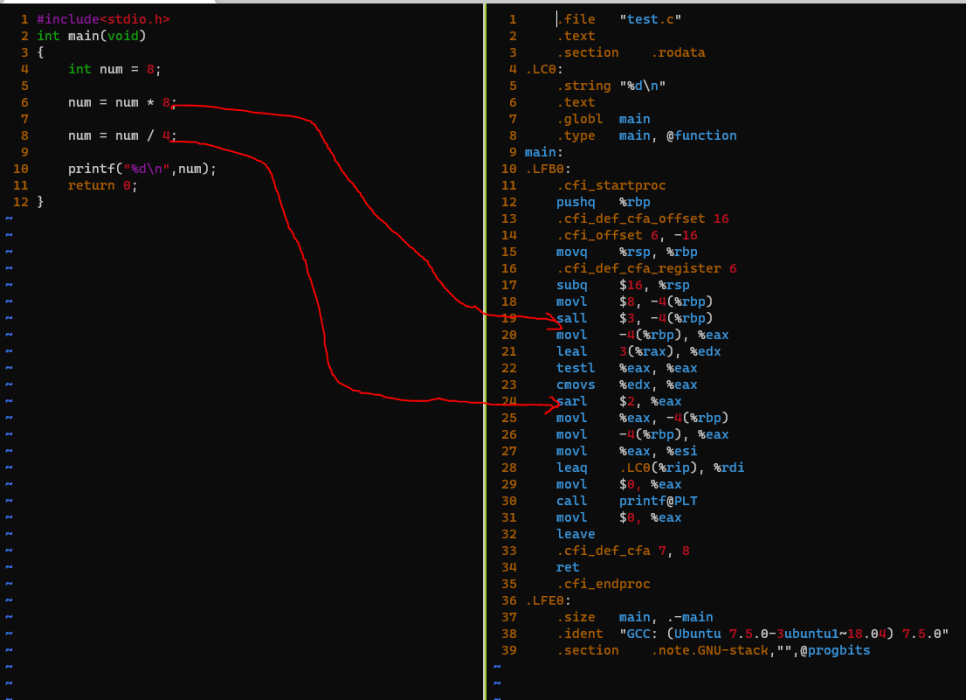
8은 shift arithmetic left num << 3 하는거 보이죠?
4는 right num >> 2 하는거 보이죠??
직접 shift를 해보겠습니다.
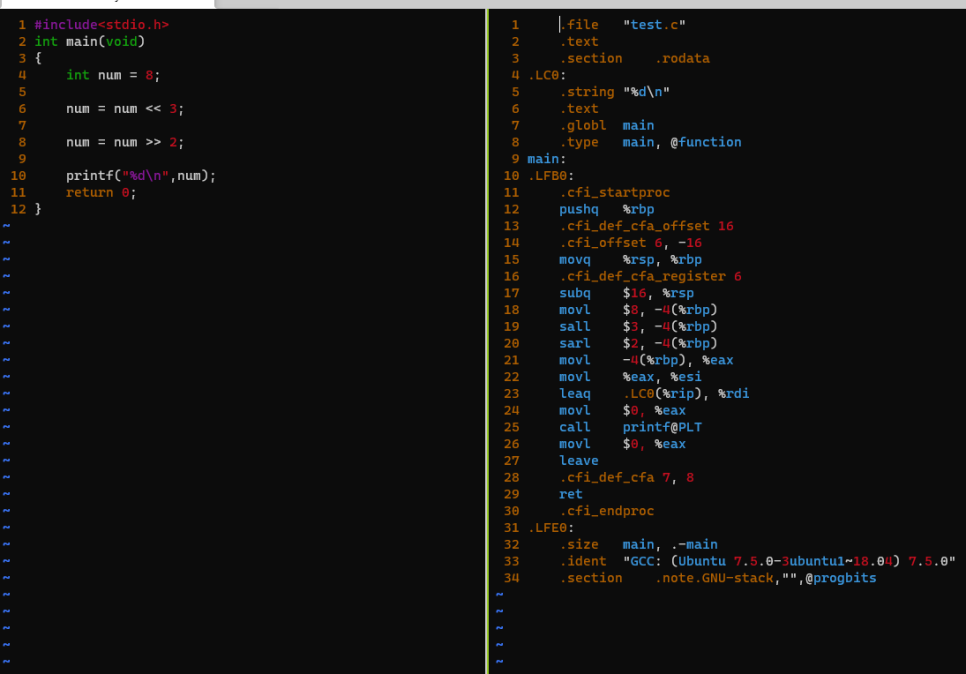
shift로 하면, 뭔가 레지스터로 옮기는 작업들이 적어지는것 같습니다.
라인수가 꽤나 차이나네요? 실행속도도 빠르겠네요 이러면.. 오 좋은거 배워갑니다 오늘!!
시스템 수업때 교수님한테 연산들을 비트로 대신 처리해주면 속도가 빨라지나요? 였습니다. (물론 제가 그렇게 생각하는 이유 좀 달아서..)
->
그 당시에 답변이, 컴파일러의 부담을 줄여주는 의미도 있고, 컴파일러보다 개발자가 code optimization을 하는것이 좀 더 좋은방법이라고
받아들여지고 있다고 하셨습니다. 대신 readability를 고려해서 주석을 달아줘야 한다고 하셨습니다.
(교수님 1년이 지나서 확인했습니다 죄송합니다..)
그럼 이만..
이제 잡니다 안녕!!

'컴퓨터 > C,C++' 카테고리의 다른 글
| [알고리즘] Prim`s algorithm. MST 구하는 2번째 방법. 프림 (0) | 2021.10.02 |
|---|---|
| [자료구조] MST를 구할 때 사용하는 크루스칼 알고리즘(Kruskal) (0) | 2021.09.30 |
| [C++] STL 기초 (range_based for문) vector (0) | 2021.01.30 |
| [C언어 기초] 범위를 넘어가는 수를 저장할때 주의할것 (int 의 합이 long long인경우) (0) | 2021.01.20 |
| [자료구조] 계산기 C코드 (괄호포함,스택) (0) | 2021.01.07 |


