저번 포스팅에 이어서 교차검증에 대해서 써보겠습니다.
Cross validation
training set이 적을때 쓰면 좋은 방법
training data의 사이즈가 작을경우에는 '교차검증' 이라고 불리는 좀 더 정교한 튜닝 기술을 사용할 수 있다.
여러개의 fold를 각각 검사해서 평균적인 성능을 낸다. 이후 어떤 k가 더 좋고 noise가 적은 결과를 낼지 예측하는것이다.
n-fold cross-validation이 있는데 여기서 fold는 하나의 그룹 으로 보면 된다.
5-fold cross-validation 을 예시로 보자.
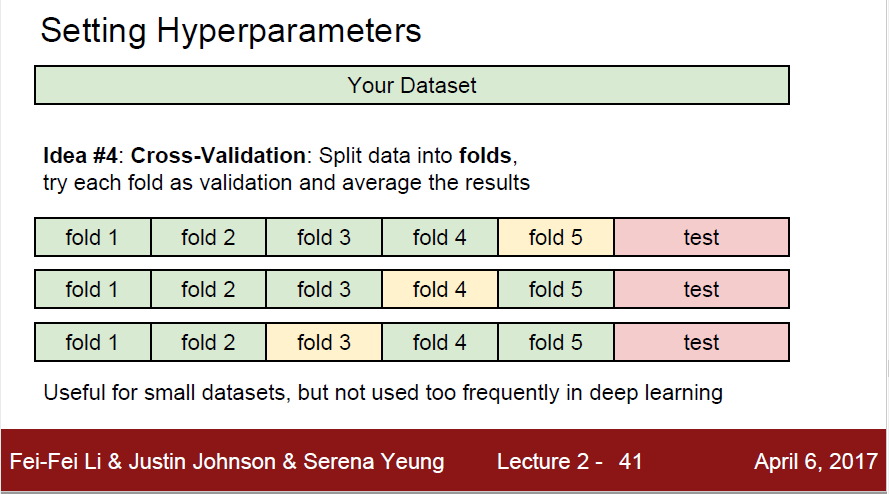
Training Data를 n개의 fold 로 나누고 1개는 validation set, n-1개는 training 으로 사용한다.
5개를 예로 들면
1. fold5 가 validation set 이라고 하자.
A,B,C,D 는 training set으로 쓰고 E를 test set처럼 사용한다.
그러면 (A,B,C,D), E 에서 성능을 한번 낸다. 그 다음 정밀도 A1 을 구한다.
2. fold4 가 validation set 이라고 하자.
(A,B,C,E) , D 로 성능을 또 낸다. 그다음 정밀도 A2를 구한다
3. fold 3에대해 같은 작업 수행
4. fold 2에 대해 같은 작업 수행
5. fold 1에 대해 같은 작업 수행
그렇게 되면 5개의 정밀도가 나오고 그것의 평균을 구한다.
그렇게 하면 최종 분류 정밀도가 나오게 된다.
아래 결과를 보고 이해해 보면 된다.

5-fold 니까 각 k 별로 5개의 결과가 나올것이다.
각 점(dot)은 결과이고 막대기는 표준편차를 나타낸다. 선 들은 평균을 나타낸다.
k마다 점이 5개이고 k=7 쯤에 제일 평균도 높고 accuracy가 0.31정도 되는걸 볼 수 있다.
따라서 kNN에서 최적의 k라고 생각하고 사용하면 된다.
그러면 k-fold cross validation만 쓰면 되는것 아닌가? 라고 생각할 수 있다.
Cross validation만 쓰면 되는게 아닌가?
안된다.
왜일까?
그냥 60%는 test하고 20%로 미리 평가 후, 마지막 실전 test 이렇게 한번만 하면 되는데 이러면 교차검증처럼 좀 더 정확하고 안전한 값을 얻을 수 없다.
하지만 교차검증은 계산량이 너무 많다.
당장 위의 5-fold만 보더라도 데이터가 10만개였으면 1-fold당 2만개씩 나뉘었을 것이다.
8만개 학습 * 2만개 test
8만개 학습 * 2만개 test
이 과정을 여러번 반복하는 것이다.
fold 수가 늘어날수록 시간이 몇배가 된다..
따라서 validation이 적으면 (수백개) 교차검증을 쓰는게 좀 더 안전하다고 한다.
실제로 볼 수 있는 fold의 개수는 3,5,10 정도이다.
k가 너무 높기만 하면 noise가 줄긴 하겠지만 class간의 경계가 불분명 해진다.
-> 이건 내 생각 이지만 k가 너무 높으면 vote해야 하는 img도 늘어나니까 시간이 더 걸리지 않으려나 라는 생각도 했다.
Nearest Neighbor classifier의 장,단점
kNN 장단점
장점 :
구현과 이해하기가 쉽다. training에 시간이 들지 않는다. O(1)
-> 배열에 넣고 index화 한다
단점 :
test time에 드는 연산 cost가 있다.
test img 하나를 training data 전체랑 비교하기 때문.
실제 사용에서는 training time에 드는 시간은 별로 신경쓰지 않는다.
test time에서 드는 시간이 줄어드는게 중요하다고 한다. 따라서 실 사용으로는 좀 부적합하다.
deep neural network 는 NN과는 완전 반대이다. training 이 길고 test가 짧다.
이런 방식이 좀 더 현실에선 바람직한 방법이다.
NN 분류기의 연산량은 아직도 연구가 되는 주제라고 한다. (2017년 게시글인데.. 지금도 하려나..)
ANN(Approximate NN) 근사 최근접 이웃 알고리즘이나 라이브러리들이 있어서 이것들이
dataset 내에서 NN을 찾는걸 가소고하 해준다.
이러한 알고리즘들은 정확도를 조금 포기하고 시/공간 복잡도에서 이득을 크게 본다.(NN을 찾을때에)
kdtree를 만들거나 k-means 알고리즘을 실행할때 사용하는 전처리 stage에 의존하는 편이다.
*난 위의 2가지 알고리즘을 모른다. 다음번에 또 볼 때 찾아봐야겠다.
어디서 쓰는게 좋을까?
NN은 '차원이 낮은 data'에서는 좋은 선택이 될 수 있다고 한다.
하지만 실생활 이미지 분류에서는 거의 쓰일 일이 없다.
Why? 실제는 고차원 물체라서 pixel의 수도 많고, 고차원의 distance는 직관적이지 않기 때문이다.

from - cs231n
위의 사진은 맨 왼쪽 original을 기준으로 다 조금씩 변형시킨 것이다.
분명 3개는 다 다른이미지인데 L2 distance로 계산해보면 sum이 다 같다고 한다. (2,3,4번이)
첫번째 사진으로부터 다 같은 거리만큼 떨어져 있다고 하는데..
딱 봐도 2,3,4는 다 다른사진이다
따라서 이 예시를 통해서 pixel로 구한 distance는 의미적으로나 지각적(perceptual) 으로나 맞지 않다고 볼 수 있다.

이 사진은 픽셀기반 distance가 맞지 않다는 또 다른 예시이다.
t-SNE 시각화 디법을 사용해서 보여주는 예시라고 한다.
*t-SNE
https://lvdmaaten.github.io/tsne/
아래 사이트를 참고하면 된다.
뭔지 모르겠지만 고차원 dataset의 차원을 축소해주는 기술인것 같다.
CIFAR-10 예시를 2차원으로 임베딩해서 보여준 예시인데
근처에 있는 이미지 일수록 L2 distance가 굉장히 가깝다는 뜻이다.
근데 동그라미 친것을 보면 뭔가 이상하다. 새와 자동차가 비슷한것으로 분류가 된다.. 뭐지 이게..
가까이 있는 이미지들은 보편적 색깔의 분포나, 배경색에 영향을 많이 받는다고 한다.
이미지들의 실제 의미(class)와는 관계 없이..
그러면 이런 배경이나 다른 종 에 관계 없이 알맞게 clustering을 이루게 하려면 어떻게 할까?
라는 의문을 남기고 더이상 내용이 없다.
pixel을 넘어선 다른 것들이 필요하다며 끝난다...
===END=====
한시간 짜리 강의인데 뭐 이렇게 배우는게 많은지..
그냥 교수님이 아는 정보를 다 말하고 우리는 다시 공부하면서 이해하는것 같다..
후.. 그럼 이만..

'컴퓨터 > Computer Vision' 카테고리의 다른 글
| [Vision] CS231n 2-3 Linear classification, Score function, template matching .. (0) | 2021.01.18 |
|---|---|
| [Vision] CS231n 2-1 kNN(최근접 이웃), L1 distance.. (0) | 2021.01.13 |
| [Vision] CS231n - 1 Intro (0) | 2021.01.04 |

